Tworząc mniejsze lub większe projekty generalnie mamy do czynienia z projektowaniem, implementacją (czyli kodowaniem) i wdrażaniem. Nie są to jednak jedyne etapy pracy programisty.
 | |
| howtogeek.com |
Trzeba tu wyodrębnić wiele pośrednich etapów zamkniętych w iteracjach (czyt. zapętlonych), powtarzanych do momentu osiągnięcia zamierzonego celu. Są to między innymi: testowanie, dokumentacja, optymalizacja. Każdy z tych etapów będziemy starali się krok po kroku przedstawić w ramach naszego bloga.
Na każdym z tych etapów można popełnić błąd.
Błędy takie jak:
- nie zrozumienie oprogramowywanego zagadnienia domenowego
- projekt nie przewidujący elastyczności w konkretnych funkcjonalnościach
- kod niezgodny z projektem
- niewydajny lub błędny kod
W każdej z takich sytuacji konieczna jest diagnoza pochodzenia problemu. Jeśli problem domenowy został poprawnie zrozumiany i zaprojektowany program powinien już działać... No i właśnie... powinien. Ale nie działa tak jak tego byśmy sobie życzyli. Jak sobie w takim razie poradzić z "zaskakująco" niepoprawnie działającym programem?
Najprostszym rozwiązaniem jest oczywiście sprawdzenie krok po kroku jak działa program czyli trzeba go zdebugować. Techniki debugowania znane z różnych IDE wymagają osobnego artykuły. Pierwszym co przychodzi do głowy programującemu jest wyświetlić informacje na konsolę w najprostszy sposób znany od czasów HellowWorld czyli instrukcja wyświetlania na wyjście konsoli: System.out.println().
Kiedy kod programu jest już wystarczająco poprzetykany instrukcjami wyświetlania na konsolę, jesteśmy w stanie zlokalizować problematyczny fragment. Jednak ilość pracy włożonej przy dodawaniu instrukcji wyświetlania, ostatecznie zaśmiecony nadmiarowymi instrukcjami kod i konieczność jego uporządkowania już po wszystkim skutecznie zabiera czas, zmniejsza efektywność i wypala zapał do tworzenie oprogramowania.
Historycznie na początku taka sytuacja jednak była koniecznością. Logi debugowania były wysyłane do System.out natomiast błędy do System.err. W kodzie produkcyjnym debug przekierowywany był do null:
natomiast błędy do pliku z logami błędów. Jednak to rozwiązanie było binarne: logujemy albo nie. Brak możliwości dokładniejszego konfigurowania takiego systemu był dużym minusem. I wtedy pojawił się Log4j - pierwsze kompleksowe rozwiązanie rozwiązujące wszystkie wcześniejsze problemy. Wprowadziło koncept Loggera, Appendera oraz poziomu logowania. Kolejnego kroku na przód dokonali twórcy Java z firmy Sun. Podjęli oni decyzję aby dodać funkcjonalność logowania do JDK. Ale zamiast wykorzystać Log4j stworzyli jedynie API inspirowane Log4j. Niestety API to nie było do końca dopracowane i kompletne. Tak więc skończyło się na tym, że w Javie 1.4 były jedynie handlery do konsoli i pliku resztę trzeba było napisać samemu. Kolejny etap należał do Apache Commons Logging API. Miało one rozwiązać problem podwójnej konfiguracji API i frameworka logowania jednak nie było to zawsze możliwe. Ostatecznie twórca Log4j stworzył projekt Simple Logging Facade for Java, o którym jeszcze powiemy więcej w dalszej części artykułu.
Kiedy kod programu jest już wystarczająco poprzetykany instrukcjami wyświetlania na konsolę, jesteśmy w stanie zlokalizować problematyczny fragment. Jednak ilość pracy włożonej przy dodawaniu instrukcji wyświetlania, ostatecznie zaśmiecony nadmiarowymi instrukcjami kod i konieczność jego uporządkowania już po wszystkim skutecznie zabiera czas, zmniejsza efektywność i wypala zapał do tworzenie oprogramowania.
Historycznie na początku taka sytuacja jednak była koniecznością. Logi debugowania były wysyłane do System.out natomiast błędy do System.err. W kodzie produkcyjnym debug przekierowywany był do null:
/* Unix version*/
PrintStream original = System.out;
System.setOut(new PrintStream(new FileOutputStream("/dev/null")));
/* Platform agnostic */
PrintStream original = System.out;
System.setOut(new PrintStream(new OutputStream() {
public void write(int b) {
//DO NOTHING
}
}));
natomiast błędy do pliku z logami błędów. Jednak to rozwiązanie było binarne: logujemy albo nie. Brak możliwości dokładniejszego konfigurowania takiego systemu był dużym minusem. I wtedy pojawił się Log4j - pierwsze kompleksowe rozwiązanie rozwiązujące wszystkie wcześniejsze problemy. Wprowadziło koncept Loggera, Appendera oraz poziomu logowania. Kolejnego kroku na przód dokonali twórcy Java z firmy Sun. Podjęli oni decyzję aby dodać funkcjonalność logowania do JDK. Ale zamiast wykorzystać Log4j stworzyli jedynie API inspirowane Log4j. Niestety API to nie było do końca dopracowane i kompletne. Tak więc skończyło się na tym, że w Javie 1.4 były jedynie handlery do konsoli i pliku resztę trzeba było napisać samemu. Kolejny etap należał do Apache Commons Logging API. Miało one rozwiązać problem podwójnej konfiguracji API i frameworka logowania jednak nie było to zawsze możliwe. Ostatecznie twórca Log4j stworzył projekt Simple Logging Facade for Java, o którym jeszcze powiemy więcej w dalszej części artykułu.
Talk to the logger because System.out.println() ain't listening.
Z pomocą przychodzi logowanie. Czym jest logowanie?
Logowanie jest to zbieranie aktywności całego programu a więc zapisywanie kolejnych zdarzeń razem z ich stanem.
Logerem przyjęło się nazywać obiekt, który obsługuje logowanie.Jednak aby nie wynajdować koła od nowa wykorzystamy istniejące frameworki. Wszystkie rozwiązania będą bazować na tych samych założeniach.
Logowanie wymaga trzech głównych elementów:
- Logger - odpowiada za przechwytywanie w aplikacji obiektu w postaci wiadomości opisującej zdarzenie wraz z pewnymi metadanymi i przekazujący ją do właściwego frameworka. Aplikacji nie interesuje co dzieje się z wiadomością dalej.
- Formatter/Renderer - gdy fraamework przechwyci od logera wiadomość przekazuje ja Formatterowi, który ją formatuje do wydania na wyjscie. Zwykle proces sprowadza się do zamiany obiektu binarnego na String.
- Handler/Appender - Sformatowana wiadomość jest dalej przekazywana do jednego z kilku handlerów, które w zależności od konfiguracji określającej typ handlera będą przekazywać wiadomość w różny sposób, np. na konsolę, do lokalnego pliku bądź logu systemowego, do bazy danych, na szynę JMS, do gniazda sieciowego, czy wysyłając e-mail.
Co znajduje się w obiekcie przekazywanym logerowi w aplikacji? Jest to oczywiście wiadomość. Dodatkowo dołączany jest tzw. poziom szczegółowości logowania oraz w pewnych sytuacjach również wyjątek. Jak widać logowanie nie służy tylko do wyświetlania aktualnych wartości ale jest potężnym narzędziem do pełnego monitorowania stanu aplikacji w zależności od ustalonej konfiguracji. Oczywiste do kilku wiadomości wyświetlanych na konsolę println() jest wystarczające. Sam ConsoleAppender z frameworka Log4j wykorzystuje strumienie standardowe System.out i System.err. Jest nawet z tego powodu wolniejszy niż bezpośrednie wywołanie System.
Jednak właściwy system logowania dodaje różnego rodzaju możliwości konieczne przy prawdziwych aplikacjach. Chociażby by przekierowywać wyjście w różne miejsca. Można zdefiniować w konfiguracji, jaką część wiadomości chcemy wysyłać bez konieczności rekompilowania. Dodatkowo mamy znacznik czasowy (timestamp) dołączany do każdej wiadomości.
Czym jest zatem poziom szczegółowości logowania?
Poziom logowania to określenie stopnia szegółowości z jaką wiadomości będą pobierane z danego logera.
Dla każdego logera framework ustawia konkretny poziom szczegółowości. W zależności wiec od stopnia wiadomości będą dokładniejsze lub ogólne. Stopnie szczegółowości to tak na prawdę hierarchia zawierania. Idąc od najogólniejszych do najbardziej szczegółowych:
FATAL < ERROR < WARNING < INFO < DEBUG < TRACE
- Log4j:
OFF < FATAL < ERROR < WARNING < INFO < DEBUG < TRACE - Apache Commons Logging:
FATAL < ERROR < WARNING < INFO < DEBUG < TRACE - Log4j2
FATAL < ERROR < WARN < INFO < DEBUG < TRACE - Logback
OFF < ERROR < WARN < INFO < DEBUG < TRACE - SLF4j
ERROR < WARN < INFO < DEBUG < TRACE - Java Logging API
SEVERE < WARNING < INFO < CONFIG < FINE < FINER < FINEST
What are the main logging frameworks / APIs ?
Poniżej znajduje się opis najważniejszych i najczęściej wybieranych fameworków logowania.
- Apache Commons Logging (ACL) - Nie jest tak naprawdę frameworkim a jedynie wrapperem na framework. A więc sam nie może działać za to umożliwia wymienne stosowanie frameworków podpinanych pod Apache Commons Logging. Jest to szczególnie przydatne gdy rozwijamy biblioteki, które mają działać pod dowolnym frameworkiem logowania. Taki model działąnia zapewnia elastyczność w dobrze dowolnego frameworka.Popularność: DUŻA
- wynika z połączenia w starszych projektach z Log4j - Java Logging API - Jest częścią Java SE (JRE). Jak sama nazwa wskazuje nie jest frameworkiem a jedynie API dostępowym do frameworka. Frameworki, które będą kompatybilne mogą zostać załadowane do JVM i udostępnione w postaci API. Istnieje również domyślna implementacja frameworka Java Util Logging (JUL) z dostępem przez JL API, dostarczana z Oracle JVM. Nie jest to jednak JL API.Popularność: ŚREDNIA
- wynika z opóźnionego wejścia i braku konkurencyjności z innymi frameworkami - Log4j - Dość leciwe narzędzie powstałe jeszcze przed JUL. Nie wspiera SLF4j. Stabilne ale nie rozwijane. Twórca Ceki Gülcü stworzył następcę: Logback-a oraz SLF4j.Popularność: BARDZO DUŻA
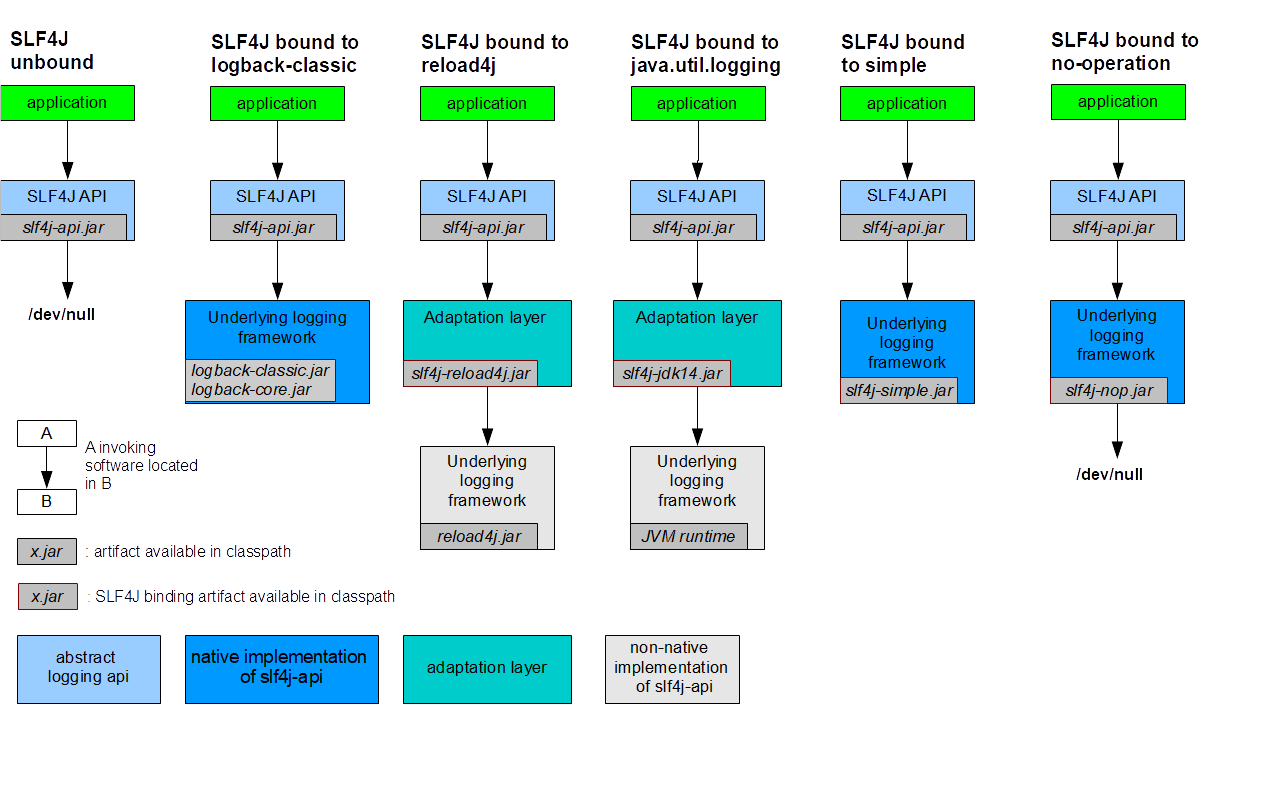
- w starszych projektach - SLF4j (Simple Logging Facade) - Jest to API logowania w Javie dostarczane za pomocą wzorca fasada. Stworzono przez twórcę Log4j jako stabilniejsza alternatywa do Apache Commons Logging. Poodobnie jak ACL daje zmniejsza stopień powiązania (coupling) pomiędy API a implementacją. Obsługuje: JUL, Log4j(aczkolwiek nie implementuje on całego API SLF4j), Logback, Log4j2 (wspiera wszystkie funkcje API SLF4j)Popularność: DUŻA
- w nowszych projektach; szczególnie przy wykorzystaniu Logback - Logback - Następca Log4j. Warto wybierać go w nowych projektach >>Zamiast Log4j << wraz z SLF4j zamiast ACL
Popularność: DUŻA
- w nowych projektach połączonych z SLF4j - Log4j2 - Następca Log4j. Nie jest pisane przez twórce Log4j oraz SLF4j i Logbacka. Jednak ma wszystkie możliwości Logbacka i implementuje w pełni SLF4j.Popularność: NISKA
- Bardzo nowe rozwiązanie ale posiada wszystkie funkcjonalności Logback-a oraz implementuje w pełni API równoważne do SLF4j (połączenie wymaga adaptera).
More on logging levels.
Przyjrzyjmy się poziomom logowania. W zależności od frameworka różnią się one jednak nieznacznie. Od drobnych różnic w nazewnictwie dla tego samego poziomu np. ERROR/SEVERE przez dodawanie poziomów ekstremalnych typu FATAL, po dość kuriozalne rozdrobnienie FINE/FINER/FINEST.
Skupimy się w tym artykule bliżej na poziomach logowania SLF4j. W odniesieniu do klasycznego ale i leciwego już log4j, SLF4j używa pięciu spośród sześciu poziomów logowania obecnych w log4j: ERROR, WARN, INFO, DEBUG, TRACE. Poziom FATAL opuszczono ponieważ framework logowania nie powinien być miejscem gdzie decyduje się o przerywaniu aplikacji. Stąd nie ma różnicy pomiędzy ERROR i FATAL z punktu widzenia logera. Z drugiej strony twórcy SLF4j oferuję jednak bardziej ogólne rozwiązanie w postaci tagowania wiadomości logera. Taki jest cel np. markera "FATAL". Wówczas poziom ERROR z markerem FATAL jest mapowany na kategorię FATAL z Log4j. O markerach więcej w kolejnej sekcji. W przypadku gdy framework posiada inne API niż SLF4j, SLF4j dostarcza moduły łączące do log4j, JCL i java.util.logging tak aby odwołania do API danego frameworka były przekierowywane jak by były kierowane do SLF4j.
 |
| SLF4j.org |
How to use logging levels?
- TRACE -
Mało używany. Najdokładniejszy z poziomów a więc i potencjalnie najobszerniejszy wynik. Z tego względu rzadko stosowany nawet na etapie produkcji oprogramowania.
Przykłady:
Zrzut całej hierarchii obiektów, logowanie stanu podczas każdego obrotu dużej pętli itd. - DEBUG -
Wydarzyło się coś normalnego i nieznaczącego. Coś co nie powinno zaciemnić poziomu INFO.
Wszystko to co nie ma znaczenia biznesowego. Każda wiadomość przesyłana a pomaga wyizolować problem, zwykle podczas tworzenia oprogramowania oraz fazy QA (Quality Assurance, patrz też Test Driven Developement).
Przykłady:
Do monitorowania IN/OUT najważniejszych i złożonych metod oraz wewnętrznych punktów zwrotnych wykonania ich kodu; Nowy użytkownik się zalogował; Wyrenderowano stronę; Zaktualizowano cenę; - INFO -
Wydarzyło się coś normalnego ALE ZNACZĄCEGO. Informacje, które potrzebne są w dużych ilościach do śledzenia konkretnego problemu. Ogólnie dowolne zdarzenie z działania produkcyjnego systemu obsługiwane w dużych ilościach.
Przykłady:
Zdarzenia z cyklu życia systemu (start, stop systemu). Zdarzenia związane z zarządzaniem sesją i jej cyklem życia np. logowanie, wylogowanie. Ważne zdarzenia typu połączenie do bazy danych czy wykorzystanie zewnętrznego API. Uruchomienie codziennego zadania aktualizacji danych; Typowe wyjątki warstwy biznesowej np. nieudane logowanie dla niepoprawnych danych uwierzytelniających. - WARN -
Gdy pojawia się NIEOCZEKIWANE zdarzenie techniczne albo biznesowe, które może wpłynąć na funkcjonowanie klienta ale nie wpłynie na jego działanie, być może działanie będzie w sposób ograniczony. Ważne i pilne natomiast dla osób odpowiedzialnych za wsparcie wdrożonego oprogramowania aby określić efekty takiego zdarzenia.
Przykłady:
Plik konfiguracyjny się nie wczytał ale zostały zastosowane ustawienia domyślne; Cena została wyliczona ale jako wynik ujemny więc zamieniono ją na zero; - ERROR -
Wykonanie zadania powierzonego programowi nie może zostać ukończone.
System ma problem a klient już nie może dalej działać albo za chwile nie będzie mógł. Interwencja wymaga zaangażowania ludzi natychmiast.
Przykłady:
Problemy, które mają prawo budzić w środku nocy dyżurnego ze wsparcia aplikacji. E-mail z fakturą nie został wysłany; Nie wyrenderowano strony; Nie można zapisać danych do bazy;
Najważniejszy jednak nie jest dobór poziomu logowania a zapewnienie czytelnego kontekstu i znaczenia przekazywanych przez log informacji. Dla przykładu zwykle potrzebny jest identyfikator wątku aby można go było śledzić. Zwykle również warto dołączać informacje z logiki biznesowej do wątku jak choćby identyfikator użytkownika. W wiadomości logu powinno być tyle informacji ile jest konieczne aby dokładnie zlokalizować dane zdarzenie i jego parametry. Pamiętać przy tym należy aby nie przeładować logu by był on również czytelny.
Przykład:
- Źle: "NoConfigInput exception caught"
- Dobrze: "NoConfigFile exception caught while attempting to use remote config at 212.182.x.x as usrID=55555."
SLF4j cool stuff
Markery są specjalnymi zdarzeniami, które loger może odfiltrować w ramach ogólniejszych poziomów logowania. Markery są częścią API SLF4j ale z frameworków wspiera Logback oraz Log4j2.
MDC("Mapped Diagnostic Context") jest mapą przechowywaną przez logujący framework, do którego kod aplikacji może dodawać pary typu klucz-wartość a te z kolei mogą być dodawane do wiadomości logera. MDC może być również bardzo pomocne przy filtrowaniu wiadomości lub wywoływaniu zdarzeń.
How to do logging in Java - example.
Najbardziej przydatne wydaje się być opisanie przykładu wykorzystania SLF4j. Jako powszechnie zaakceptowanego, wykorzystywanego i uniwersalnego narzędzia.
Najpierw zainstalujmy SLF4j dzięki Mavenowi:
Najpierw zainstalujmy SLF4j dzięki Mavenowi:
org.slf4j slf4j-api 1.7.5
Oto przykład SLF4j HellowWorld :
package com.acme.HelloWorld;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class HelloWorld {
public static void main(String[] args) {
Logger logger = LoggerFactory.getLogger(HelloWorld.class);
logger.info("Hello World");
}
}
Instancja logera dodawana jest przez LoggerFactory, klasę zdefiniowaną przez SLF4J API. Zmienna logger dostaje przypisaną instancję klasy Logger dzięki wywołaniu statycznej metody getLogger z klasy LoggerFactory. Metoda main następnie wywołuje metodę info logera przykazując jej argument w postaci napisu "Hello world". Mówimy wówczas, że metoda main zawiera instrukcję poziomu logowania INFO z wiadomością "Hello world".
Powyższy przykład nie jest specyficzny do SLF4j bo jest to tylko fasada. Tak samo wyglądało by to gdyby to był to jeden z obsługiwanych przez SLF4j frameworków np. Log4j czy Logback.
Teraz można już uruchomić jak normalną aplikację. Jednak w wyniku dostaniemy komunikat:
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder". SLF4J: Defaulting to no-operation (NOP) logger implementation SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
To ostrzeżenie jest ponieważ nie dostarczono odpowiedniego wiązania do frameworka w class path. Tak więc trzeba dodać owy binding, np. w postaci slf4j-simple zawierającym prostą implementację wysyłającą wszystkie logi na System.err.
Wynik będzie następujący:org.slf4j slf4j-simple 1.7.5
Oczywiście dla innej implementacji konieczny będzie właściwy jej pakiet wiązań (binding). Żeby na przykład zamienić framework logujący z zmieniamy binding java.util.logging na Log4j wystarczy zastąpić slf4j-jdk14-1.7.5 na slf4j-log4j12-1.7.5.
Loger jest zwykle prywatną zmienną finalną dodawaną w następujący sposób:
package com.acme.examples;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
*
* @author acme.com
* @version 1.0
*/
public class Hello_SLF4J {
private final Logger slf4jLogger = LoggerFactory.getLogger(Hello_SLF4J.class);
/**
* Print hello in log.
*
* @param name
*/
public void sayHello(String name) {
slf4jLogger.info("Hi, {}", name);
slf4jLogger.info("Welcome to the HelloWorld example of SLF4J");
}
/**
* @param args
*/
public static void main(String[] args) {
SLF4JHello slf4jHello = new Hello_SLF4J();
slf4jHello.sayHello("acme.com");
}
}
Należy jednak pamiętać, że w metodach statycznych ten sposób się nie sprawdzi. Należy wówczas każdą taką metodę rozpoczynać żądaniem logera:public static doStuff() {
final org.slf4j.Logger log = org.slf4j.LoggerFactory.getLogger(ThisClass.class);
log.info("in doStuff()");
}
Zauważmy, że pod puste nawiasy klamrowe {} możliwe było podstawienie wartości zmiennej name. Zmienne wyświetlane przez logera mogą być też np. wyjątkiem. Liczba wystąpień wzorca {} w wiadomości jest po prostu zastępowana przez wartości. W logerze metody logujące są przeładowane swoimi formami pobierającymi jedną, dwie bądź więcej wartości. Jest to proste rozwiązanie dodatkowo dające zysk w postaci wydajności w przypadku wartości o kosztownych metodach toString(). Wynika to z faktu, że gdy jest wyłączone logowanie np na poziomie DEBUG, framework logujący nie musi określać reprezentacji napisowej wyświetlanych wartości na tym poziomie.
Ostatnią ważną zauważenia sprawą jest fakt, że frameworki logujące są optymalizowane pod kontem nie zakłócania pracy aplikacji logowanej i przy właściwym stosowaniu się do opisanych wskazówek (czyt. stosowania odpowiednich poziomów logowania na odpowiednim etapie implementacji i wdrożenia oprogramowania logowanego) nie będą wpływały na efektywność pracy aplikacji.
More Examples:
- JUL
- http://www.vogella.com/articles/Logging/article.html
- http://tutorials.jenkov.com/java-logging/logger.html
- http://www.onjava.com/pub/a/onjava/2002/06/19/log.html
- http://docs.oracle.com/javase/7/docs/api/java/util/logging/Logger.html
- Apache Commons Logging
- http://peaktechie.blogspot.com/2011/09/commons-logging-tutorial.html
- http://javarushi.blogspot.com/2012/04/how-to-use-apache-commons-logging-with.html
- Logback
- http://www.javacodegeeks.com/2012/04/using-slf4j-with-logback-tutorial.html
- http://logback.qos.ch/manual/introduction.html
- Log4j
- http://logging.apache.org/log4j/1.2/manual.html
- http://www.tutorialspoint.com/log4j/log4j_sample_program.htm
- http://www.dzone.com/tutorials/java/log4j/log4j-example/log4j-example.html
- Log4j2
Conclusion
Logowanie jest podstawowym narzędziem przy pracy nad oprogramowaniem. Podstawowe przypadki użycia to:
- debugowaniu oprogramowania podczas fazy deweloperkiej
- znajdowanie bugów podczas fazy produkcyjnej
- tworzenia danych do celów statystycznych
- śledzenia dostępu przy analizie bezpieczeństwa
i wiele mniej lub bardziej ogólnych zastosowań.
Logowanie w Jave jest tyle samo sztuką co rzemiosłem. Dobór właściwego API i narzędzi wymaga dobrego warsztatu natomiast formatowanie wyniku logów, format wiadomości, dobór tego co logować oraz jakiego poziomu logowania użyć dla każdej logowanej informacji wymagają dużego doświadczenia i nie jest już prostą sztuką. Zaznaczyć przy tym trzeba, że źle dobrane logi w aplikacji mogą wpłynąć znacząco na jej wydajność co w przypadku np. aplikacji typu aukcji akcji giełdowych gdzie opóźnienia stanowią istotny problem.
Problem wydajności logowania nie dotyczy jednak tylko aplikacji z domeny finansów czy giełdy ale każdej podstawowej aplikacji typu klient-serwer dla której szybkość komunikacji jest bardzo ważna a logi są konieczne.
Problem wydajności logowania nie dotyczy jednak tylko aplikacji z domeny finansów czy giełdy ale każdej podstawowej aplikacji typu klient-serwer dla której szybkość komunikacji jest bardzo ważna a logi są konieczne.
No comments :
Post a Comment